「文字コードのはなし」の連載その2、その名も「文字コードのはなし」です。
もくじ
– Shift_JISのはなし
– 文字コードのはなし(本稿)
– ASCIIのはなし
– Unicodeのはなし
– UTFのはなし
– BOMのはなし
文字コードのはなし
Shift_JISの話が終わったから、今度はUnicodeの話だ!と息巻く前に、文字コードについての基礎を抑えておきたいと思います。
ところで「文字コード」という言葉は使いどころによって意味が異なるため、かなり曖昧な表現であると文字コード界隈ではもっぱらの噂です。
このまま文字コードという言葉を用いて話を進めると混乱の元になりかねないので、「文字コード」といった時に意図しうる次の2つの言葉の意味を区別しましょう。
– 文字集合
– 符号化方式(エンコーディング)
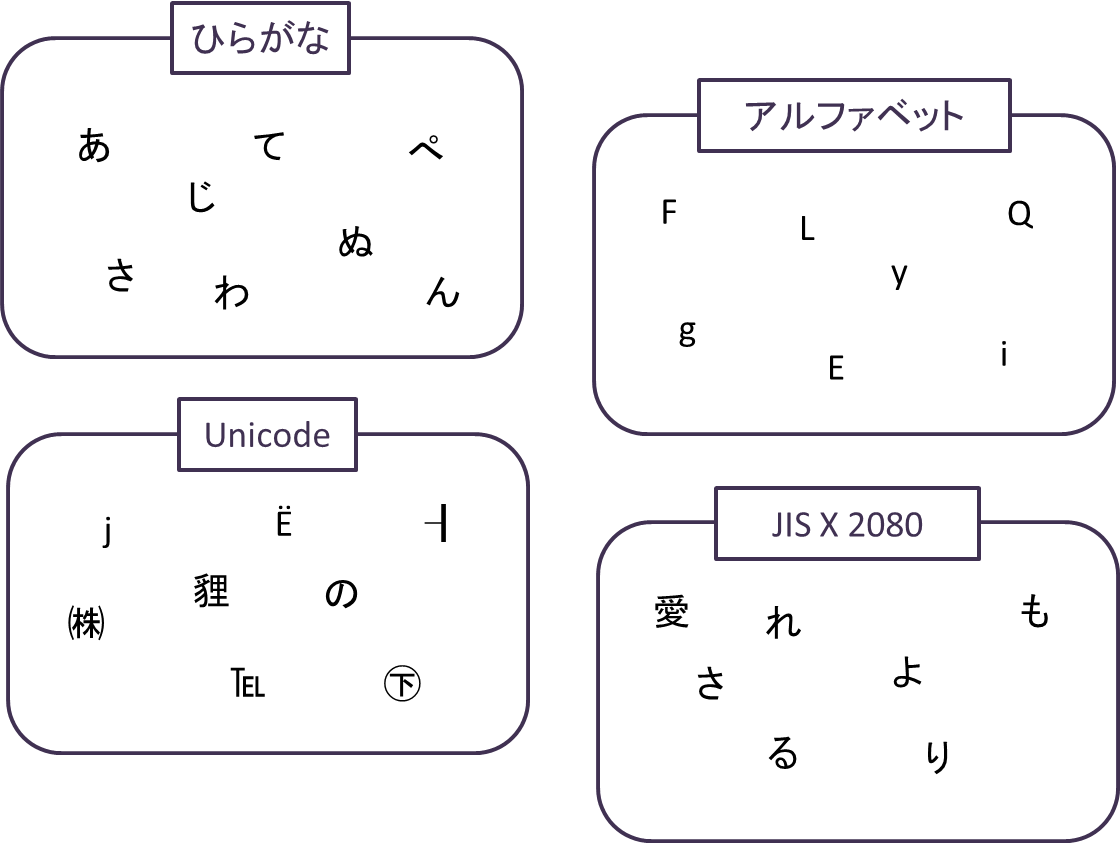
文字集合とは、文字を要素とする集合のことです。禅問答みたいですが、具体例を挙げるならば「ひらがな」は「あ、い、う、え、お、か、…、ん」という”要素”で構成される”集合”と言えます。同様に「アルファベット」は「A, a, B, b, C, c, …, Z, z」という要素で構成されている集合と言えます。
実際に存在する用語で例えるなら、「Unicode」や「JIS X 2080」などは文字集合を表す言葉です。Unicodeは「世界の文字を表せるようにしよう!」をモットーに策定された文字集合のため、収録されている文字要素は、パスパ語から、タイ・ヴェト語、マニプリ語や統合カナダ先住民音節まで多種多様な文字が含まれており、今なお拡張されています。対してJIS X 2080は日本語表記を目的とした日本工業規格であるため、日本語を記述する上で支障のない7000種類弱の文字を要素とする文字集合です。
{kind=link}
一方、符号化方式(エンコーディング)というのは、よく聞くUTF-8やUTF-16、Shift_JISやEUC-JPのことを指します。そして、これらの符号化方式には、対応する文字集合が必ず存在します。
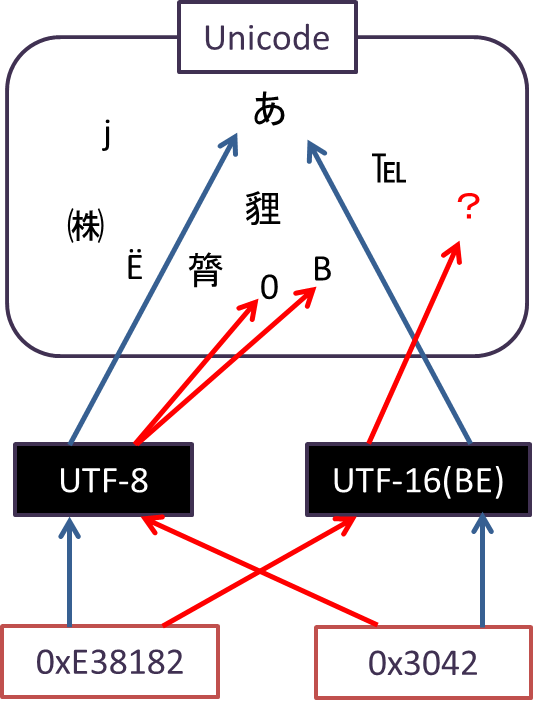
例えば、UTF-8、UTF-16といった符号化方式は、Unicodeという文字集合の中にある文字1つ1つをコンピュータが理解できるようにどのように表すのかを規定したものです。Unicodeという文字集合の中で「あ」という文字を指し示したい場合、UTF-8では「0xE38182」、UTF-16(BE)では「0x3042」と表現します(BEという謎の宣言が出てきましたが、ここでは無視してください)。逆を言えば、エンコーディングがUTF-8として保存されたファイルは、内部的には「0xE38182」として保存されているということです。
ちなみにここで出てきた「0x」という接頭辞は、その後に続く文字列が「16進数を表していますよ」という意味です。
{kind=link}
ここで、例えばUTF-8で「あ」と入力したファイルをUTF-16(BE)形式で開いてしまったとしましょう(上図0xE38182から伸びた赤矢印)。そうすると、開いたあなたの目に飛び込むのは「あ」ではなく、行き場を失って何も文字を指し示せなくなったUTF-16(BE)の姿です。というのも、UTF-16のチカラでは「0xE38182」という16進数を、何らかの文字に変換することができないのです。
順を追って説明すると、UTF-16という符号化方式は、例外はありますが16bit(16進数4ケタ分。例:F39D)で1文字を表現するものであるため、まず「E38182」の先頭16bitである「E381」が何かの文字に変換できないか試そうとします。この時、UTF-16において「E381」に対応する文字は(今のところ)Unicodeには存在しないため、「文字なし」ということで何も表現できずに終了してしまいます。残った「82」も16bitに満たないのでUTF-16では何も出来ません。これが、「0xE38182」に対してUTF-16が何も出来なかった理由です。
{kind=link}
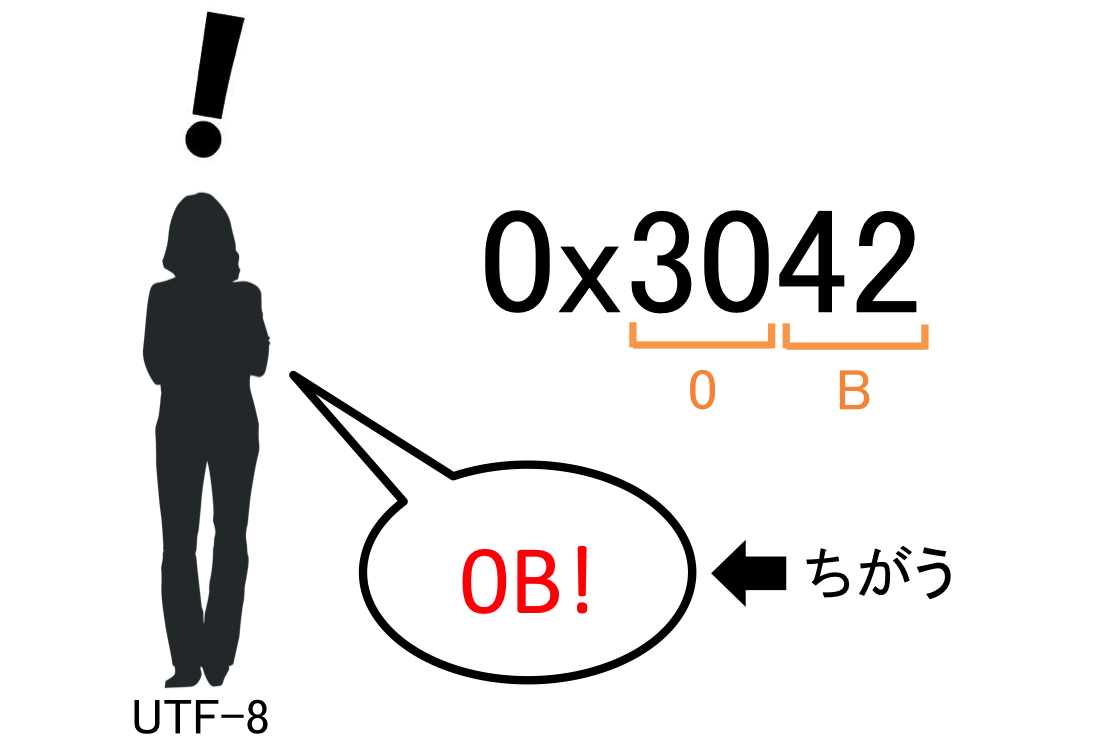
逆に「あ」と入力したUTF-16(BE)のファイルをUTF-8で開いてしまった場合は、「0B」と表示されてしまいます。表示こそされるものの、「あ」とは似ても似つかない文字ですし、文字数も違います。これは、UTF-8が8bitから32bitの可変長(1文字が8bitの時もあるし、32bitの時もある)で1文字を表すという仕組みに従った結果です。
つまり、UTF-8さんが「3042」という16進数4ケタに遭遇した時、まず先頭8bitの「30」が1文字に変換され、次にそれに続く「42」が1文字に変換されます。このように処理されることで、30は「0」に、42は「B」に変換され、最終的に「0B」という文字列が完成するということです。
{kind=link}
長々と説明してきましたが、ここで言いたかったのは結局、「文字集合」と「符号化方式(エンコーディング)」を区別して使いましょうということです!これでアナタも「Unicodeでエンコードしてね」なんていう曖昧さを多分に含んだ表現は生涯しないことでしょう。
ところで余談ですが、Microsoft WindowsのNotepad.exeでは、ファイル保存時に文字コードが選べます。
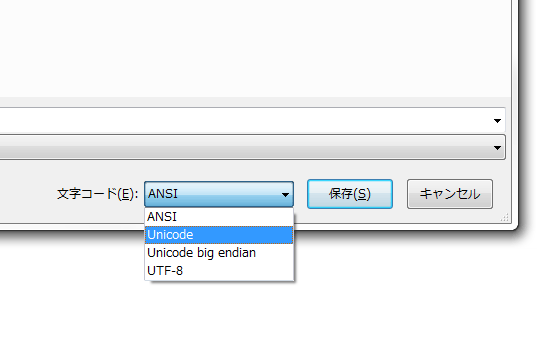{kind=link}
見たところ、ANSI・Unicode・Unicode big endian・UTF-8が選べるようです。この奇妙な選択肢については、文字コード界隈でよく語られています。というのも、先ほどお話したとおり、UTF-8は符号化方式であり、Unicodeは文字集合を意味していますから、本来なら並べて書くことができないからです。
ちなみに、ここでUnicodeを選択するとUTF-16で保存されます。したがって、ここはUTF-16と書くのが適切と言えますね。また一番上の「ANSI」はwindows-31J(CP932)で保存されます。ANSIという名前をなぜ使っているかは謎です(誰か教えてください)。