こんにちは。
クリエイティブAI研究所所属フロントエンドエンジニアの夏見です。
AI初心者の私ですが、いま自分が持っている技術で何かできないかと、IBM WatsonのAPIを使ってみることにしました。
今回作ってみたのは、IBM Watson APIsのVisual Recognitionを利用して、自分がWebブラウザで開いたページにどんな画像が含まれているか(=自分がどんなページを閲覧しているか)を記録するChrome拡張機能です。
IBM Watson Visual Recognitionについては過去、当ブログ内でも取り扱っているので詳しくは こちら に任せます。
今回はJavaScriptで使用するので、↓のようにWatsonを蹴っ飛ばします。
ちなみにChrome拡張機能を作成する際はES6記法がそこそこ使用できます。
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 |
// Watsonの認証情報等 const API_URL = 'https://gateway-a.watsonplatform.net/visual-recognition/api/v3/classify'; const API_KEY = 'xxxxx'; const API_VERSION = '2016-05-19'; /** * WatsonAPIを蹴っ飛ばす * @param {string} url 画像のURL * @param {Function} callback XHR成功時に実行 * @param {Function} errCallback XHR失敗時に実行 */ const kickWatson = (url, callback, errCallback) => { let xhr = new XMLHttpRequest(); xhr.onreadystatechange = () => { if(xhr.readyState === 4) { if(xhr.status >= 200 && xhr.status < 300){ callback(JSON.parse(xhr.responseText)); } else { errCallback(xhr.responseText); } } } xhr.open('POST', `${API_URL}?api_key=${API_KEY}&version=${API_VERSION}&url=${url}`, true); xhr.send(); } |
こちらのデモ を見ていただくと分かりやすいのですが、Visuak Recognition APIからは画像に何が写っているかの”分類名”と”スコア”が返ってきます。
この分類名ごとにスコアを足し算していけば、自分がどんなページを閲覧しているか分かるはずです。
本当はスコアに閾値を設けて一定以下は無視した方がよさそうですが、今回はあえてそのままにしています。
さて結果ですが、およそ2日間ほどまわしてみたところ、↓のようになりました。(クリックで大きくなります)
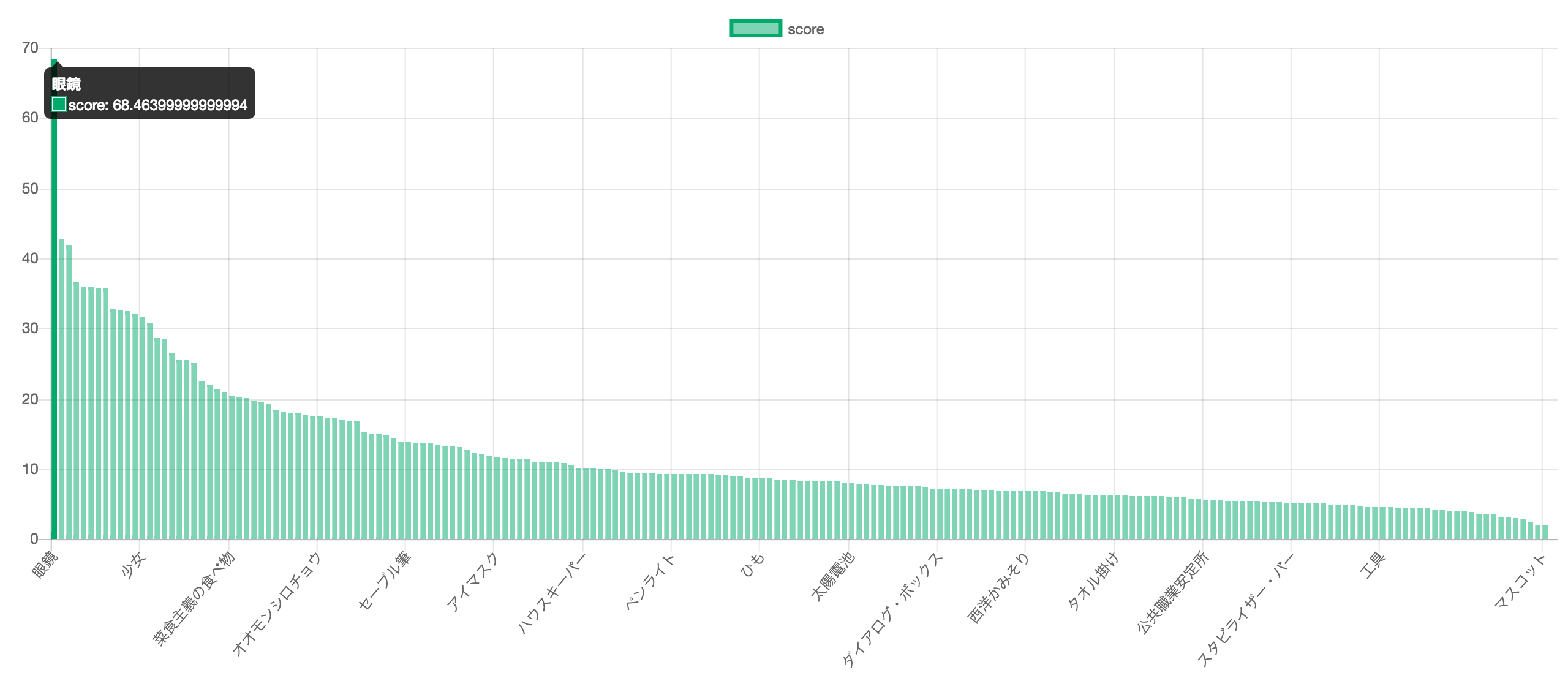
第1位は『眼鏡 (68.46pt)』でした。
あまり心当たりがないのですが、もしかしたら閲覧したページに写っていた人物がみんな眼鏡をかけていたのかも知れませんね。
3位には『高級雑誌 (41.88pt)』というものが入っていました。
ちょうど仕事で雑誌を取り扱っていたので、まったく的外れという訳ではないようです。
今回は30日お試しプランの範囲内だったので、すぐに上限に達しないよう1ページあたり解析する画像をランダムで5枚に絞っていましたが、全部解析したら結果も変わりそうです。
また、ロゴや単純な図形(矢印など)は外した方が精度があがりそうです。
今後も人類の進歩に貢献しないものを一生懸命作っていきたいと思います。