こんにちは。
先日、いろいろあってWord2Vecというものを勉強する機会があったのですが、自分への備忘録も兼ねてその時得た知見的なものを書いていきたいと思います。
Word2Vecとは?
「単語の意味や文法を捕らえるために、単語をベクトル表現化して次元を圧縮したもの」
です。いきなり難しいですね、、
例えば、「ハワイ」「中田英寿」「PHP」という言葉があったとします。そして、それぞれの単語に、「暑い」「プログラム」「サッカー」という属性情報を、度合いとともに付随していきます。
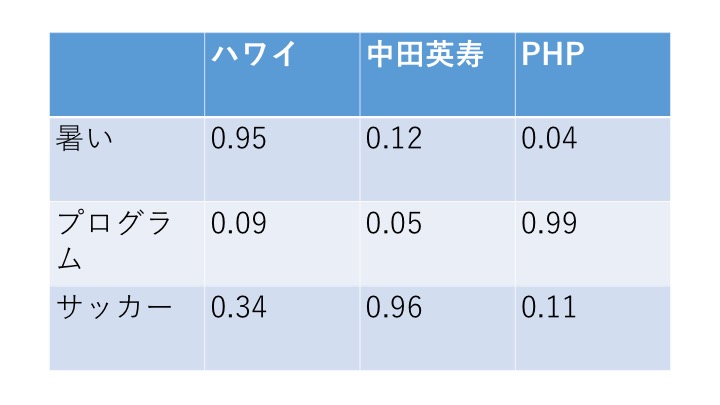
「ハワイ」は「暑い」ところなので、「暑い」の度合いが高めですが、「中田英寿」と「PHP」は特に関係のない属性なので度合い低めです。「PHP」はプログラミング言語なので、「プログラム」の度合い高めで、他の単語にとっては度合い低めです。「中田英寿」は当然「サッカー」の有名選手ですので「サッカーの度合い高め、「ハワイ」はそんなに関係なさそうですが、南国ということもあり30%強くらいの度合いはあるかもしれません。
といった感じで、上記の表の度合い自体は完全に僕の私見でつけていますが、「単語」に対して「属性」を、「度合い」と一緒に付随することで、単語をベクトル表現化することができます。
これによって、「言葉の足し算・引き算」と「類似単語の類推」が可能になります。
言葉の足し算・引き算
下記の式をご覧ください。
「イチロー」-「野球」+「サッカー」=「ロナウド」
「空」-「上」+「下」=「海」
こういった言葉の足し算・引き算は、人間ではなく機械が理解しようとすると大変ですが、Word2Vecの考え方を用いると演算が可能になります。
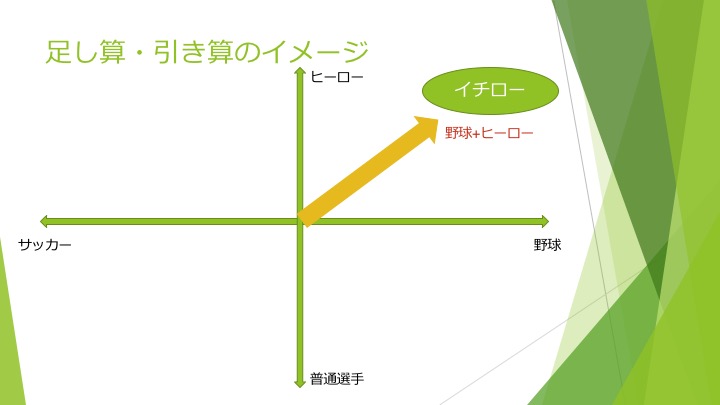
例えば、上記図では、「イチロー」という単語を「野球」と「ヒーロー」という2属性のベクトルで表しています。この「イチロー」という単語から「野球」属性を引き、「サッカー」属性を足すと、下記のような図になります。
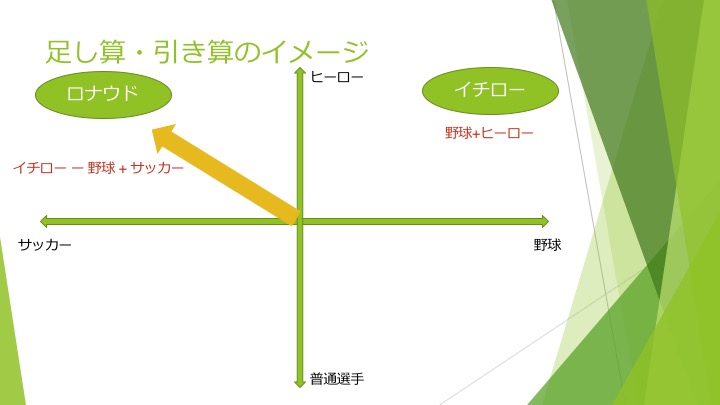
このように、ヒーロー側に向いているベクトルはそのままに、野球からサッカーに横のベクトルが切り替わります。そして、切り替わった先に存在している単語が、例えば「ロナウド」になるわけです。上記の例では「ヒーロー」「スポーツ」という2属性、2次元での話でしたが、実際、単語にはもっと多数の属性が付与されており、より複雑な、何百次元レベルの演算が必要になります。
そういった何百次元の計算・学習を行ってくれるツールを、Googleが開発してくれているので、今回はそれを使ってみたいと思います。
「イチロー」-「野球」+「サッカー」という式を実現するために、ツールに「野球」「イチロー」「サッカー」という順番で入力すると、下記のようなレスポンスを返してくれます。
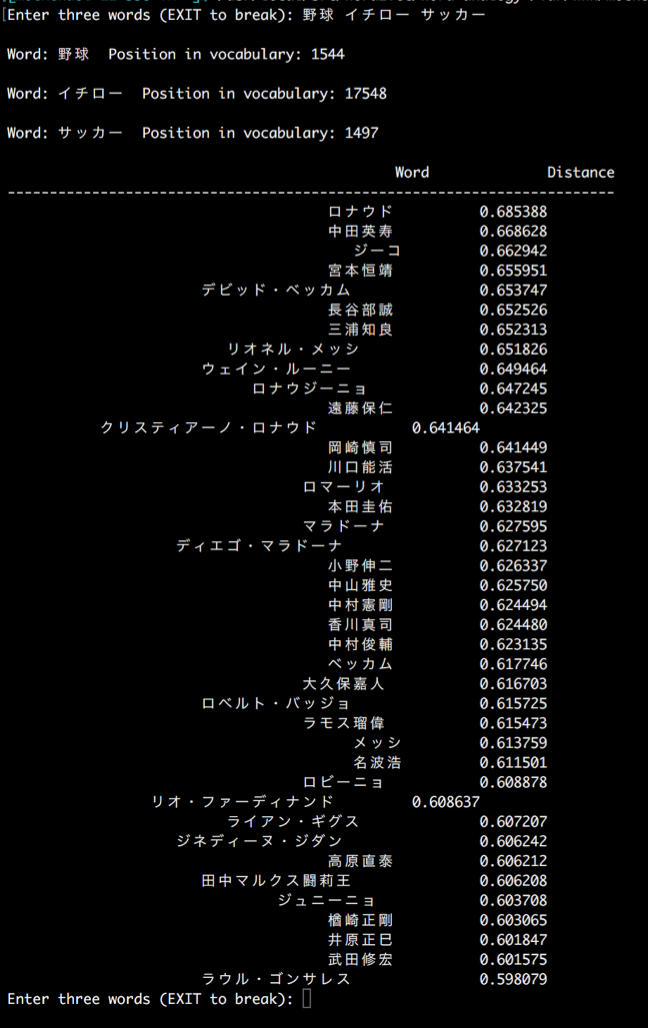
類似度のような度合いも一緒に返してくれるのですが、上位の方には、やはり「ロナウド」や「ジーコ」「中田英寿」などが来ますね。
もう一例試してみます。
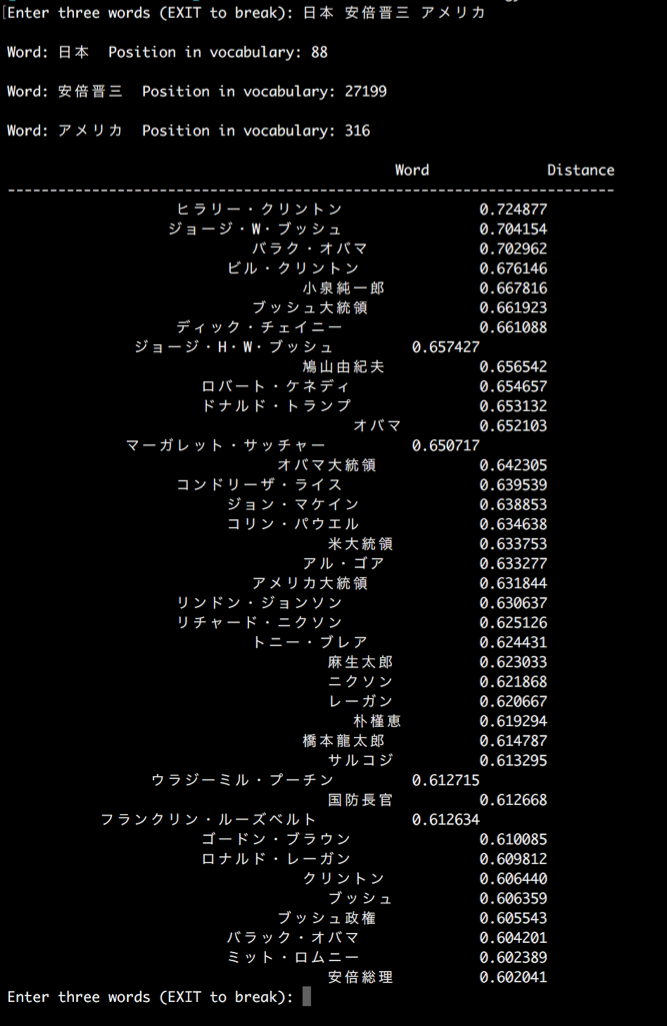
今ですと、「ドナルド・トランプ」が上位に来ることを期待してましたが、まさかのヒラリーさんの方が上位ですね。みたいな感じで、結構遊ぶことができます。
類似単語の類推
Googleが開発しているWord2Vecツールのもう一つの機能として、類似単語の類推があります。もう一度最初の表を表示します。
「PHP」という単語に対して「プログラム」という属性が高めに設定されていますが、同じ「プログラム」属性が高い単語を引っ張ってくることができます。
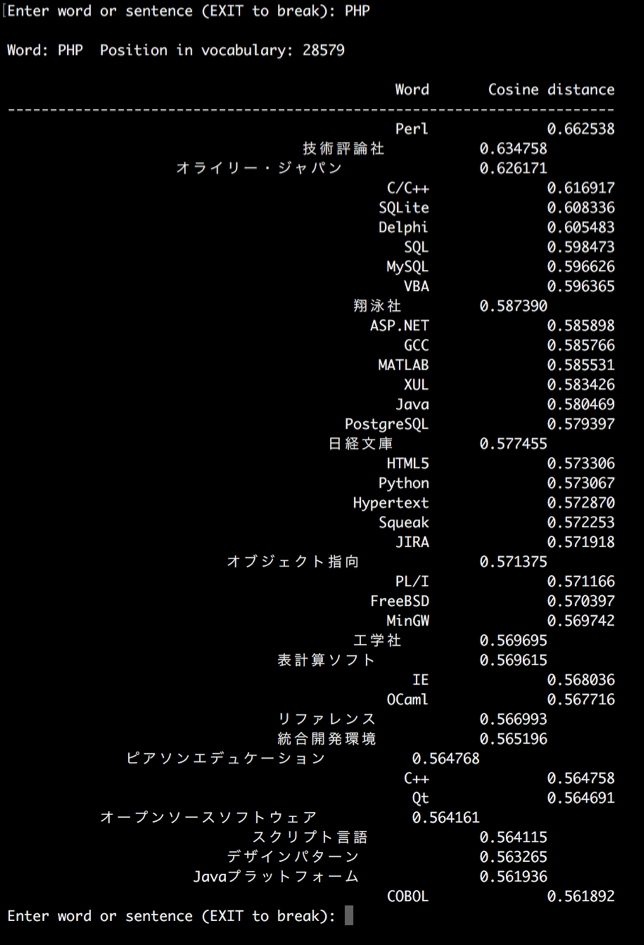
ちなみに、PHPという単語の中で「プログラム」という属性値が一番高かったから上記のような一覧を取得することができましたが、、例えばPHPの「言語」属性を指定して類似語を出す、のように属性を指定して類似語を算出するようなことは、Word2Vecではできません。あくまで「単語と単語の意味的な距離」を利用する技術なのです。
環境構築
Word2Vecは、ただそれ単体ではただのツールに過ぎなくて、言葉の足し算引き算や類似語類推は行ってくれません。単語のデータを学習させる必要があります。
今回は、こちらの記事を参考にさせていただきながら、Wikipediaの記事データ全文を学習させてみました。手順としては、
Wikipedia全文データ用意→wp2textを使用しWiki全文データからタグ情報などを除去→mecabを使いWiki全文を品仕事に分かち書きにする→Word2Vecに学習させる
という流れです。今回は環境構築の手順については割愛しますが、参考にさせていただいた記事を元に進めて、そこまで苦労せずに環境ができました。
学習ロジック
今回、Word2Vecを行うために、WikipediaのテキストデータをGoogleが開発したツールに大量に学習させているわけですが、「単語と単語の意味的な距離」は下記図のような考え方で算出されています。
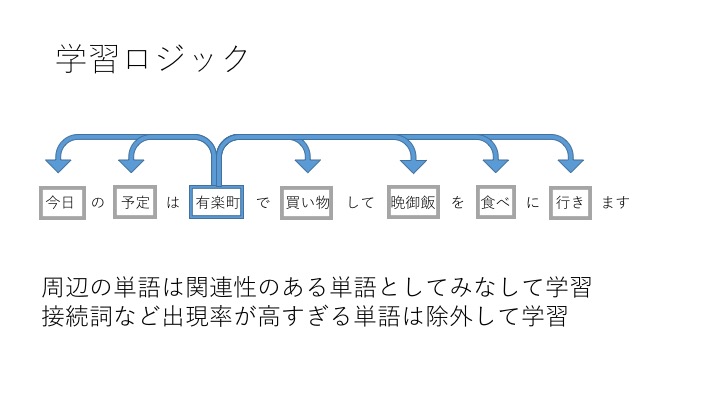
このように、一文の中に含まれている単語同士は、近しい意味の単語として捉えるようなロジックが組まれています。なのでWord2Vecに文章を学習させる場合は、mecabなどで品詞ごとに分けて(分かち書きにして)学習させる必要があるのです。また、接続詞や副詞など、文章に頻出する単語については除外されるようなロジックも組まれています。
まとめ
今回はWord2Vecという考え方自体と、ツールを紹介させていただきました。紹介した使い方としては「言葉の足し算・引き算」と「類似語の類推」くらいでしたが、工夫をすれば単語のクラスタリングなど、まだまだいろんなことができそうだと感じました。自然言語処理って難しいですけど面白いので、引き続きいろいろと勉強していきたいと思います。
それでは!